Hay un problema incómodo en la inteligencia artificial que durante mucho tiempo se ha ignorado porque el resultado parecía suficientemente bueno.
Los modelos de lenguaje responden bien. A veces incluso impresionan.
Pero en entornos reales, eso no es suficiente.
👉 Porque no necesitas respuestas plausibles
👉 Necesitas respuestas correctas, trazables y basadas en tu contexto
Y ahí es donde aparece RAG.
El problema que RAG viene a resolver
La dependencia exclusiva de modelos entrenados externamente introduce un riesgo claro en entornos corporativos:
- información desactualizada
- falta de contexto específico
- imposibilidad de trazabilidad
- riesgo de cumplimiento
Esto no es un problema técnico menor sino un bloqueo directo para adoptar IA en serio.
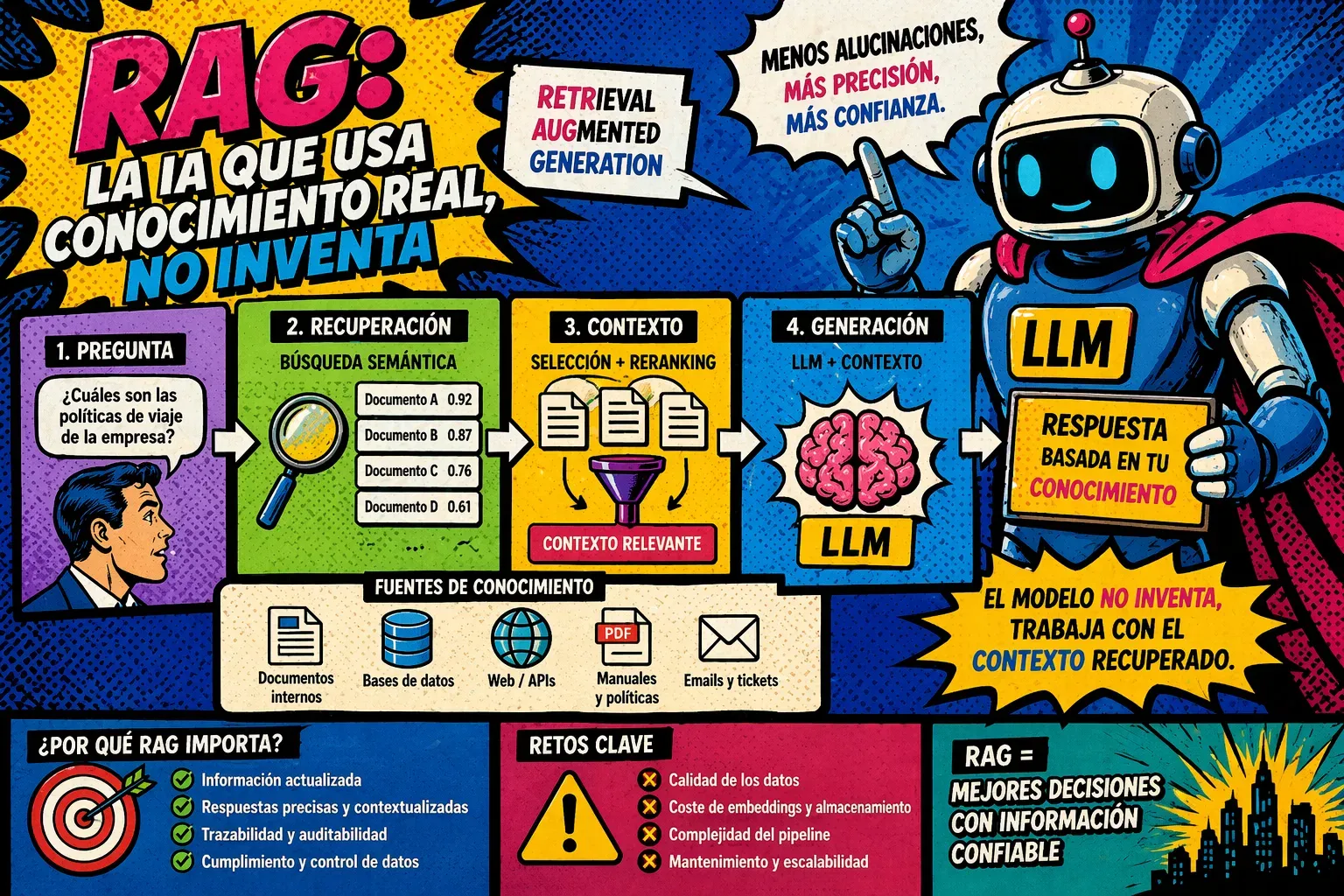
Qué es RAG
Es una arquitectura.
Lo que hace es simple de explicar, pero complejo de diseñar bien:
- Recupera información relevante
- La inyecta como contexto
- Genera una respuesta basada en ese contexto
👉 El modelo deja de responder “desde lo que sabe”
👉 Y pasa a responder “desde lo que encuentra”
La arquitectura real detrás de RAG
Aquí es donde empieza el trabajo de verdad.
Un sistema RAG típico introduce nuevas piezas en tu arquitectura:
1. Ingesta y segmentación (chunking)
La calidad del sistema depende directamente de cómo divides la información:
- chunks demasiado grandes → pierdes precisión
- chunks demasiado pequeños → pierdes contexto
2. Embeddings y base de datos vectorial
Cada fragmento se transforma en una representación matemática.
Esto permite:
- buscar por significado (no por texto exacto)
- recuperar información relevante aunque no coincida literalmente
Aquí entran componentes como:
- vector databases (Pinecone, Weaviate, etc.)
- modelos de embeddings
3. Recuperación + reranking
No basta con encontrar resultados.
👉 el reranking
Un filtro adicional que:
- ordena por relevancia real
- reduce ruido
- mejora la calidad del contexto final
4. Generación controlada
El LLM entra aquí.
Pero con una diferencia fundamental:
👉 No genera libremente, genera condicionado por el contexto recuperado
Esto cambia completamente su comportamiento.
Lo importante: el modelo deja de “inventar”
Este es el punto más importante del documento:
el modelo final no inventa información, trabaja con el contexto proporcionado
Esto tiene implicaciones enormes:
- trazabilidad
- auditabilidad
- confianza
- cumplimiento normativo
👉 RAG no mejora el modelo, hace el sistema usable en empresa
Problemas reales que introduce
RAG no es gratis.
Coste
- generación de embeddings
- almacenamiento
- consumo de tokens
Complejidad
- pipeline de datos
- sincronización de información
- mantenimiento de índices
Calidad de datos
- duplicados
- inconsistencias
- documentos similares
👉 Si tu dato es malo, RAG amplifica el problema.
Escalabilidad y decisiones arquitectónicas
👉 Tras validar el caso de uso, tiene sentido moverse a soluciones open source o autogestionadas:
- control de costes
- control de datos
- flexibilidad arquitectónica
👉 Pero también implica:
- más responsabilidad operativa
- más complejidad
Lo que cambia realmente
RAG no es una mejora incremental.
👉 Es el paso de IA como asistente genérico a IA como sistema experto sobre tu conocimiento
Por lo tanto, el valor de RAG no está en generar mejores respuestas, está en controlar de dónde vienen.