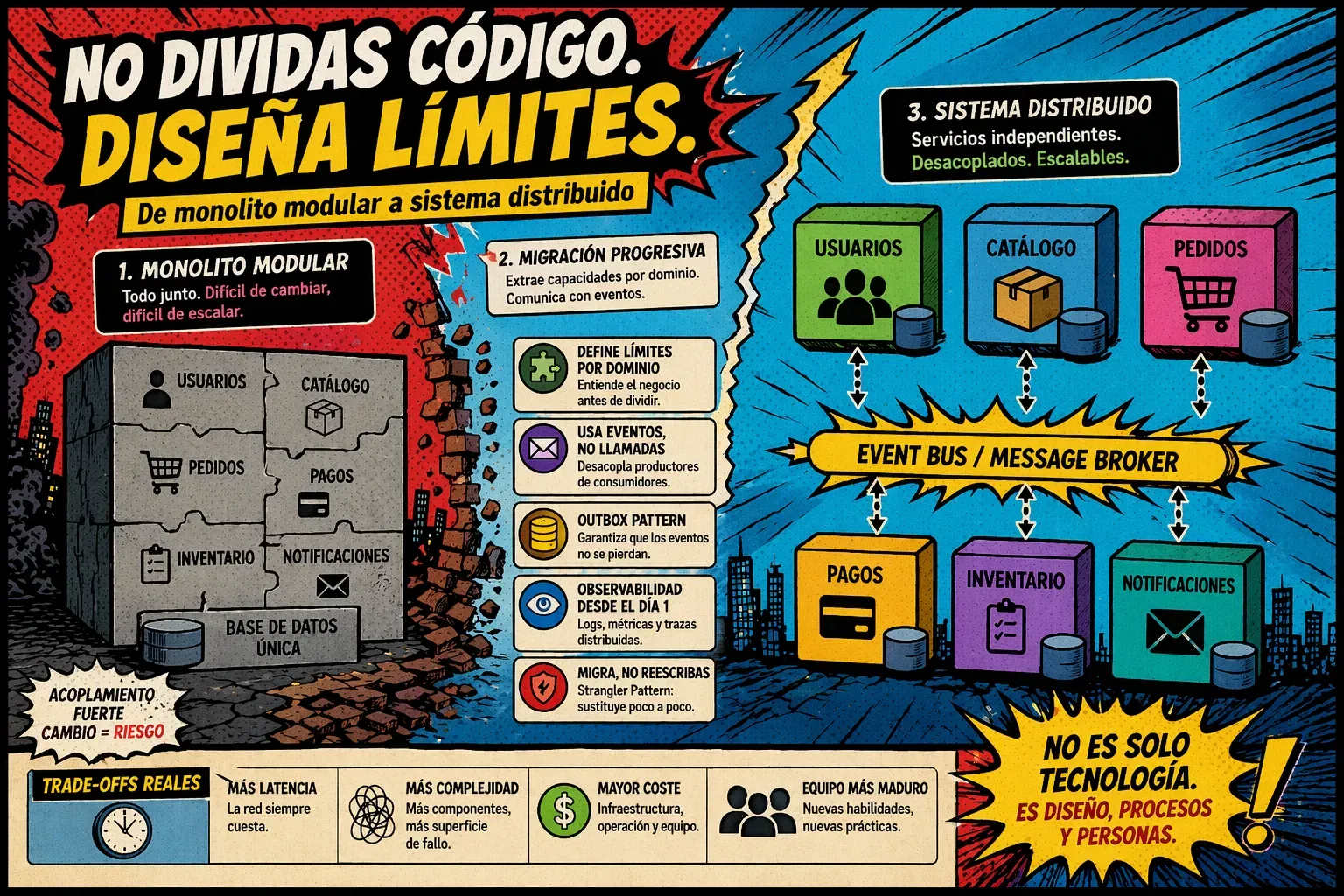
Hay una decisión que muchas organizaciones toman demasiado pronto y casi siempre por las razones equivocadas: “tenemos que ir a microservicios”.
Y casi nunca es verdad.
No porque el destino sea incorrecto, sino porque el punto de partida no está preparado para ese salto. El problema no es que un monolito exista. El problema es que demasiados equipos llegan a él tarde, mal modularizado y con una deuda interna tan alta que cualquier cambio cuesta más de lo que debería. Entonces aparece la idea de distribuir, como si repartir el sistema en más piezas fuera a corregir automáticamente lo que ni siquiera está bien resuelto dentro del proceso actual.
El problema no es el monolito
El error más común en este tipo de conversaciones es tratar al monolito como si fuera una antipatrón en sí mismo. No lo es. Un monolito puede ser una solución perfectamente válida cuando el dominio está bien modelado, las responsabilidades están separadas y la evolución del sistema sigue siendo manejable.
Lo que de verdad genera dolor es un mal monolito: lógica mezclada, dependencias cruzadas, módulos que solo existen en el diagrama y cambios que obligan a tocar demasiadas cosas a la vez.
Si eso es lo que tienes, migrarlo a microservicios no resuelve el problema sino que lo traspasa.
Antes de distribuir, hay que modularizar
La lección importante es simple: antes de pensar en un sistema distribuido, necesitas entender y separar el sistema que ya tienes. Eso exige modularidad real. No carpetas separadas. No paquetes con nombres bonitos. Modularidad de verdad.
Eso implica definir responsabilidades, aclarar dependencias y entender qué parte del negocio pertenece a cada módulo. Si dentro del monolito no puedes identificar límites razonables, tampoco vas a poder convertir esos límites en servicios independientes.
El error clásico: dividir por intuición técnica
Cuando una organización decide “empezar la migración”, suele aparecer un patrón reconocible. Se crean servicios que suenan correctos: usuarios, catálogo, pedidos, pagos. Sobre el papel parece una separación limpia. En la práctica, muchas veces sigue existiendo la misma base de datos, la misma lógica repartida en varios sitios y la misma necesidad de coordinar despliegues porque nada es realmente autónomo.
Ese es uno de los peores escenarios posibles: un monolito distribuido.
Ahora tienes latencia de red, más complejidad operativa, más puntos de fallo y sigues sin independencia real. Has añadido coste sin capturar beneficios.
El cambio de verdad: consistencia eventual
Para mi el salto importante entre monolito y sistema distribuido no es tecnológico. Es mental.
En un monolito estás acostumbrado a una transacción, un commit y una consistencia prácticamente inmediata. En un sistema distribuido, eso desaparece como garantía general. Empiezas a trabajar con múltiples procesos, múltiples almacenes, fallos parciales y asincronía. Eso obliga a aceptar algo que a muchos equipos les cuesta muchísimo: la consistencia eventual no es un defecto accidental, es una consecuencia natural del modelo.
Y cuando no se diseña pensando en eso, el sistema parece funcionar… hasta que deja de hacerlo.
Pedidos en estados intermedios, pagos confirmados pero no reflejados, stock actualizado tarde, notificaciones fuera de orden. Esto no aparece al principio, sino cuando el sistema ya importa.
Otro error muy habitual es plantear la transición como una reescritura global. Además de cara, suele ser una mala idea. Obliga a asumir demasiado riesgo al mismo tiempo y convierte la migración en un proyecto paralelo que compite con el negocio real.
Por lo tanto, migrar bien casi nunca significa reescribirlo todo…
La alternativa sensata es una migración progresiva. Extraer capacidades concretas, aislarlas bien, introducir nuevos flujos poco a poco y convivir temporalmente con el monolito. No es un enfoque espectacular. Pero es defendible. Y, sobre todo, reduce el riesgo de romper lo que ya funciona mientras construyes lo siguiente.