Hay una idea que se repite demasiado en equipos técnicos:
“Si queremos escalar, tenemos que ir a microservicios”
Y casi siempre es una mala señal.
No porque los microservicios sean un problema.
Sino porque esa idea o decisión suele aparecer antes de haber etendido realmente el contexto del problema:
👉 modelar correctamente el sistema
El error de base: dividir antes de entender
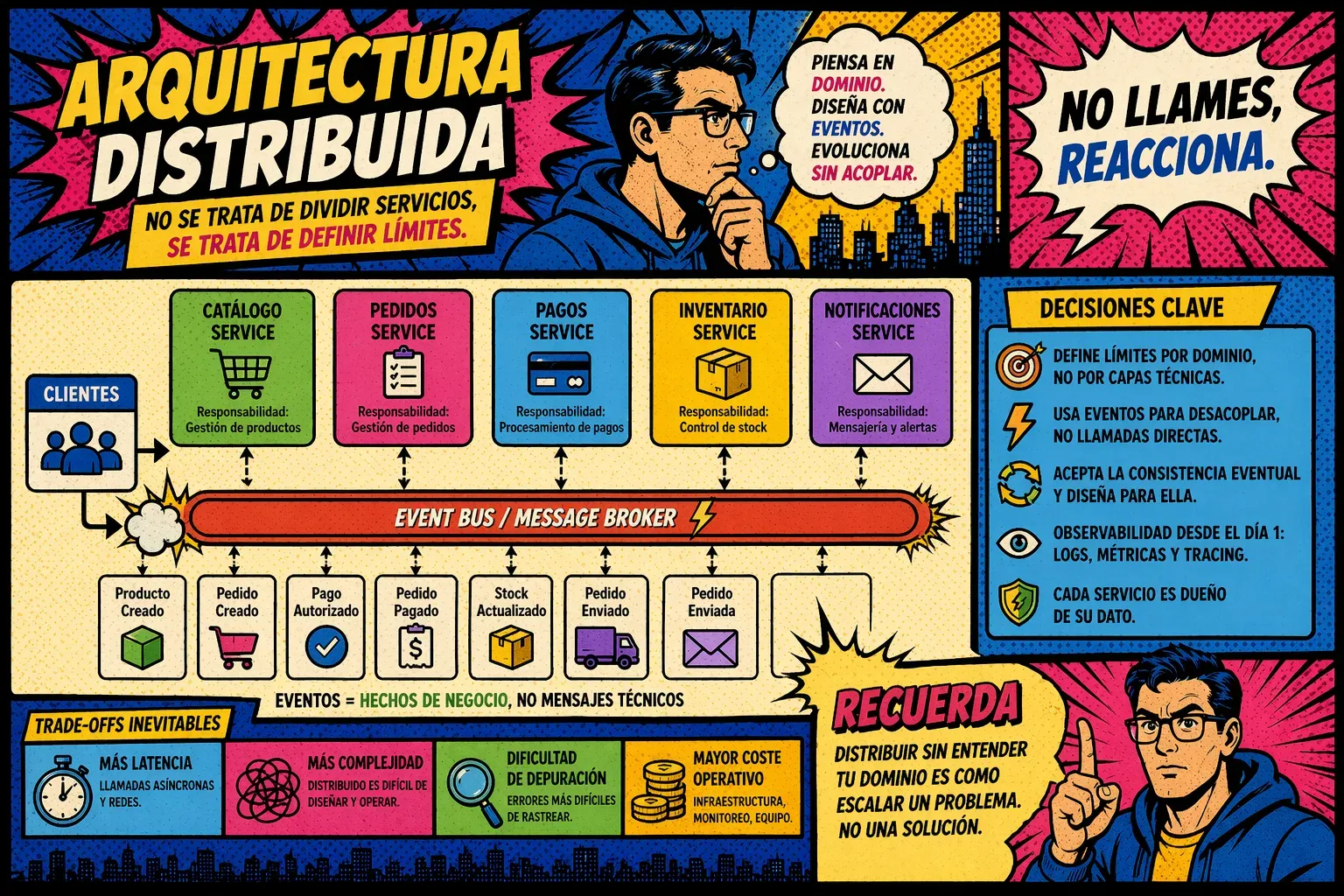
El documento deja algo claro desde el inicio del ejercicio práctico:
antes de hablar de distribución, hay que entender qué hace realmente el sistema.
Y aquí es donde falla la mayoría de iniciativas.
Se intenta dividir:
- por capas técnicas
- por endpoints
- por módulos existentes
Pero no por dominio.
Resultado:
- servicios acoplados
- dependencias cruzadas
- cascadas de llamadas
- sistemas difíciles de evolucionar
👉 Por lo tanto, has distribuido el problema, no lo has resuelto.
El verdadero punto de partida: contexto y límites
El modelado correcto empieza identificando:
- qué responsabilidades existen
- qué datos pertenecen a cada parte
- qué reglas de negocio gobiernan cada área
Esto es, en esencia, trabajar con bounded contexts, aunque el documento no lo nombre explícitamente.
La clave no es dividir el sistema.
👉 Es definir dónde empieza y dónde termina cada responsabilidad
Eventos: el cambio que introduce desacoplamiento real
Uno de los puntos más importantes del enfoque es el uso de eventos como mecanismo de comunicación.
Y aquí hay una diferencia crítica:
- llamar a otro servicio → acoplamiento
- reaccionar a un evento → desacoplamiento
Pero cuidado.
Adoptar eventos sin criterio genera otro tipo de caos:
- eventos mal definidos
- duplicidad de información
- falta de trazabilidad
El documento apunta a algo importante:
👉 los eventos deben representar hechos de negocio, no detalles técnicos
Ejemplo:
✔ PedidoCreado
❌ InsertPedidoEnBD
Consistencia: el problema que aparece cuando todo parece funcionar
En un monolito, la consistencia es “gratis”.
En distribuido, no.
Y aquí es donde muchos diseños fallan en producción.
Porque no han pensado en:
- consistencia eventual
- orden de eventos
- duplicidad
- reintentos
El resultado típico:
- datos inconsistentes
- estados intermedios
- errores difíciles de reproducir
👉 Diseñar distribuido sin diseñar consistencia es ingenuo.
El equilibrio incómodo: desacoplar vs complicar
Distribuir un sistema introduce ventajas claras:
- escalabilidad
- independencia de despliegue
- resiliencia
Pero también introduce costes:
- latencia
- complejidad operativa
- observabilidad
- debugging distribuido
👉 no todo sistema necesita ser distribuido desde el inicio
IA como apoyo (pero no como sustituto)
Un punto interesante del documento es el uso de IA para analizar y proponer estructuras.
Y aquí hay que ser claros:
✔ útil para explorar
✔ útil para generar alternativas
❌ no sustituye el criterio arquitectónico
Porque:
- no conoce el negocio real
- no entiende restricciones organizativas
- no asume consecuencias operativas
👉 La IA propone. El arquitecto decide.
Lo que realmente significa “diseñar distribuido”
No es dividir servicios.
Es tomar decisiones sobre:
- límites de dominio
- contratos
- eventos
- consistencia
- fallos
- observabilidad
Y entender que:
👉 cada decisión tiene impacto en coste, complejidad y evolución
La arquitectura distribuida no es un objetivo.
Es una consecuencia.
Cuando:
- el dominio está bien modelado
- los límites están claros
- las responsabilidades están separadas
Entonces sí tiene sentido distribuir.